Function Calling?
Nah! We got something better!

About:
"Function calling" has become the latest buzz in the world of large language models (LLMs), presenting a sophisticated approach to solving complex challenges. For those familiar with this cutting-edge feature, we have an exciting alternative. This post introduces a new method that enhances efficiency and ensures the highest quality in your solutions. Explore how this innovative approach can transform your problem-solving toolkit.
Imagine,
You want to cook certain dishes for the guests coming to your home. And you have naive bots that take your requests and execute them. You have a bot for grocery purchase. You got a helper bot that prepares the cooking ingredients. And you got a chef bot that takes specific instructions on when, what and how much to add and sense when the dish is ready.
Now you would,
-
Give specific instructions to the purchase bot, on required ingredients for the dishes that you want to prepare.
-
Give specific instructions to the helper bot, on cleaning and preprocessing of ingredients.
-
Give specific instructions to the chef bot, on how and what to prepare.
In addition to that, the naive bots recognize when it doesn’t know what to do and asks you what to do.(That’s a sign of intelligence!). This will go on until you say, “all good”.
Best case,
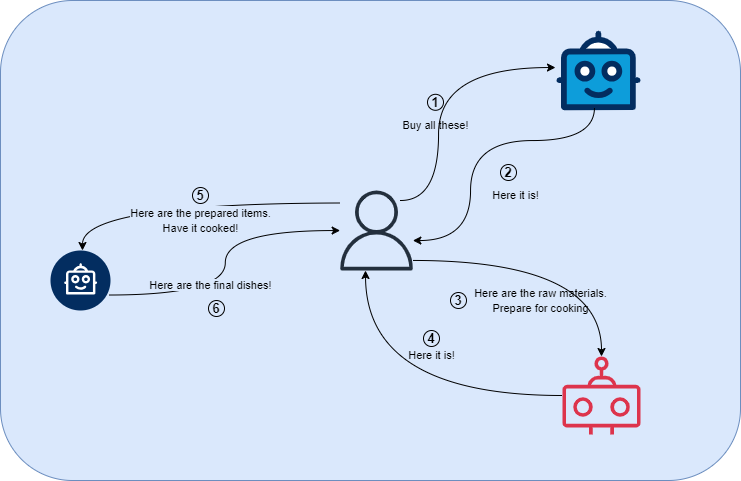
You give instructions to the shopping bot, the shop that your bot visits contains everything you want and all good!
It hands over to you the purchased items.
You go through all the purchased items and give it to the helper bot with instructions.
The ingredients are of the best quality without any wastage and the bot handles all the prep work like chopping, unpacking, etc, then passes the prepared items on for cooking.
You give it to the chef bot with instruction, the food preparation went well! And all are happy!
Not so best case,
When the shopping bot is making the purchase, the shop doesn’t have all the ingredients you want. The bot comes back with all the list of all the items in the supermarket and asks you what to do, you give the second option. And fortunately it went well this time.
When the helper bot cuts the vegetables, it finds something awful. It comes back to you to ask what to do. You direct it to use other extra veggies that you bought. It goes well.
And let’s say the preparation goes well. Overall, though it took a bit more time, by chance, you’re well within the time!
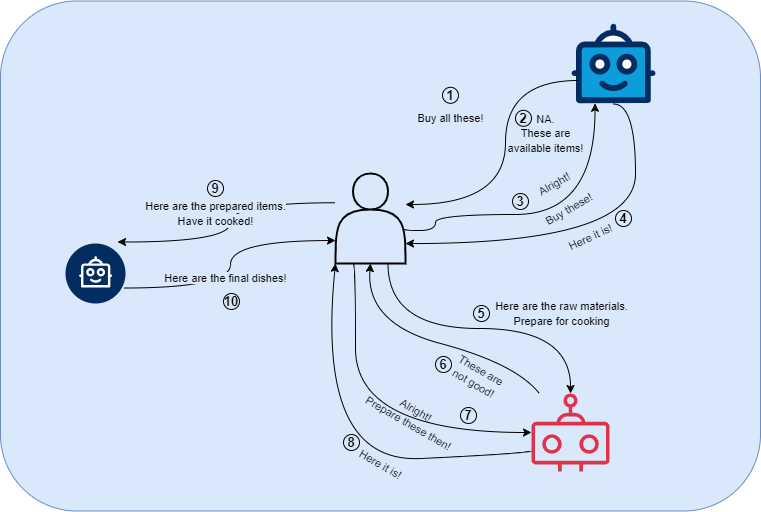
By the way, if you have noticed, “you” have to make “all” the decisions at “every point in time”. And the bots are really dumb and just executing what you say, “one step at a time”.
Okay, So?
Well!
If you could connect the dots, that's exactly how function/tool calling would work!
Where,
-
Your LLM app tells the LLM that the options(tools/functions) that the LLM has.
-
The LLM tells which tool/function to call when some input is needed.
-
The output of the current function/tool call will be passed on to the LLM along with all the available tools/functions.
-
And this will go on forever.
In the above analogy,
-
You are the LLM.
-
Each instruction to the bot is a function/tool calling.
-
And each bot mentioned above is a tool/agent executing the function call.
Your LLM is loaded with each and every small decision making and the rest of your code are dumb bots getting one instruction at a time and executing it in function calling.
And you will be like,

And, each call to LLM will need the complete history, redundant definition of support tools in each prompt, etc, adding a lot of tokens further, and increasing processing time and token cost!
True! Is there an alternative?
Certainly! If you look at it differently!
If you have your LLM return the data(instruction for each step), you are bounded by making one decision at a time and also burdening the engineering part of your LLM app with if-else for each function it asks you to call and executing it and returning the result and waiting for it to return the next data.
If you have your LLM return the code(solution to the complete problem at once), your agents are not more dumb performing one step at once. You can give it a sequence of logics, conditionals and loops. Where it can take the path dynamically by executing the code given by the LLM.
Can you be a bit more concrete?
In the above example, instead of having each bot coming back to you for every decision, what if you express the complete process and share it.
So that each bot take the small decisions without coming back to you every time.
For example, you can say
-
“Plan A”(steps to prepare Dish A), buy all these items. If it’s not of enough quantity, buy as much as it is available and for the remaining, buy ingredients for “Plan B”(steps to prepare Dish B).
-
For helper bot, if you have all for “Plan A”, start doing it. Or if the ingredients are not sufficient for “Plan A”. Prepare as much as you have for “Plan A” and prepare “Plan B” for the remaining.
And you can say all these “at once”, without the bots having to come back to you at all in the best case. And in error cases, there might be some hops.
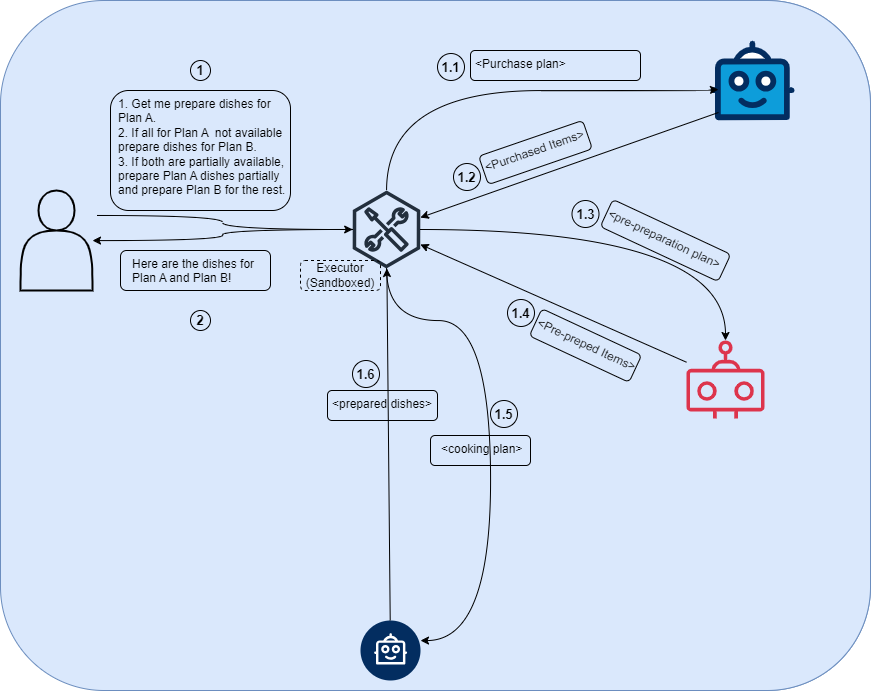
So you’re asking the LLM to generate a code?
Exactly!
So with this, you’re offloading the decision making process to the agents/tools to some extent and minimizing the roundtrips (also the token usage to a great extent!)
Well! Security? Multi-platforms?
Great questions!
You might think,
If the LLMs response is a code, I probably have to do an eval of the response coming from the LLM.
What if the LLM behaves weird and spits out some malicious code?
What if I have agents built in different languages?
You can get all of it!
It’s possible to have the LLM generate a language that can be executed securely and across any platform(Python, Javascript, Java, you name it!) that you want.
Wait! What language is that?
With s-expression based DSL, for which you can write an interpreter in less than 100s of lines of code and extend it whatever the functionality that you want.
With that,
-
You can express any arbitrary logic.
-
It’s infinitely recursive.
-
It’s json, so that each object is either a function, if not a data.
-
By itself, it's turing incomplete(no loops/recursion, conditionals out-of-the box!), but you can extend it to support anything that you want to do.
-
It’s 100% sandboxed. It’s impossible to execute some code that is not in your control.
How practical is this?
We have used it for couple of our experiments and got satisfactory results,
-
For our “Conversational Analytics”, we made the LLM to compose multiple operations(querying data, plotting and response) as a DSL. So that we’ll do ONLY ONE CALL to LLM. And the performance was around 90.7%.
-
For our P2C, we made a medium sized model to learn and talk in our DSL with a peak performance of 98% on specific use cases.
So it’s efficient as well as practical.
In addition to this, the approach is LLM agnostic. Your solution need not rely on LLMs providing function calling. If you notice the above 2 examples mentioned, the former is a OpenAI/Gemini based solution and the latter is a custom LLM based solution.
Seems good, what’s the catch?
In functional calling, you could have a generic prompt and rely on tool_calls to present in your response and go on calling the function until it’s there.
In this approach, you might have custom prompts based on the stage of the problem you’re in(if you’re designing your solution in multi-stage) and take care of the terminal condition yourself, rather than leaving it to the LLM.
You might need some additional tweaks if you have to wrap this approach in some standard frameworks such as Langchain or so. But not hard!
Further, this is not an “all-or-none” approach. If at all, you find yourself in a position where the LLM couldn’t give you the complete plan, you could break down the load of LLM by asking it to plan for a sub-part of the problem and go ahead. With that you could meet midway on using LLM between “function calling(one-decision at once)” and “complete plan at once”.
Why is it not so common then?
Think the LLM community is getting there after the recent research papers like
ReWOO, LLM Compiler, et al. And release of tools based on the research paper.
Ok, So your work is based on the ongoing research papers in the LLM world already?
Not exactly!
Our journey towards the approach was through a slightly different chain-of-thought. Which is,
- LLM generates data.
- Data can be code.
- Code can express complex logic and multiple-steps at once.
- Hence, LLM can express complex logic and multiple-step at once, without having to see the result of each step by itself.
Idea of seeing data as code, is an inspiration from Father of Artificial Intelligence around 6 decades back! Our approach differs in a way that the output of the LLM is a sandboxed extensible programming language by itself, which allows you to extend it to whatever way you want. Where you’ll gain maximum flexibility but might miss out the definitions that are there in the open source libraries like langchain’s LLM Compiler. You might have to weigh in the flexibility, learning curve and out-of-box support that you might need.
Regardless of the path, we believe we’ll all converge to a point, where we use LLM only for intelligence, in an efficient way, without overloading it with each small decision!