GraphQL: The Superior Choice
for LLM-Based Applications

In today’s rapidly evolving tech landscape, Generative AI (Gen AI) solutions are driving transformative change in how businesses handle data, interact with customers, and make decisions. However, integrating Large Language Models (LLMs) into enterprise systems requires thoughtful consideration of the right tools and infrastructure. Through an extensive empirical study, we explored the most effective ways to deliver Gen AI solutions, powered by LLMs, and identified GraphQL as the superior choice over traditional Traditional REST, Holistic OpenAPI, and Elasticsearch for structured queries.
In this blog, drawing from our in-depth collaboration with ![]() , we’ll walk you through our analysis of different integration approaches, exploring latency, token consumption, and how the combination of GraphQL and Elasticsearch optimizes both structured and unstructured queries.
, we’ll walk you through our analysis of different integration approaches, exploring latency, token consumption, and how the combination of GraphQL and Elasticsearch optimizes both structured and unstructured queries.
Scope and Solution Methodology
Our work is grounded in an empirical study focused on building scalable, efficient Gen AI solutions for the modern enterprise. The primary Gen AI solutions considered include:
- Copilot: A personalised assistant offering conversational analytics in media and other domains.
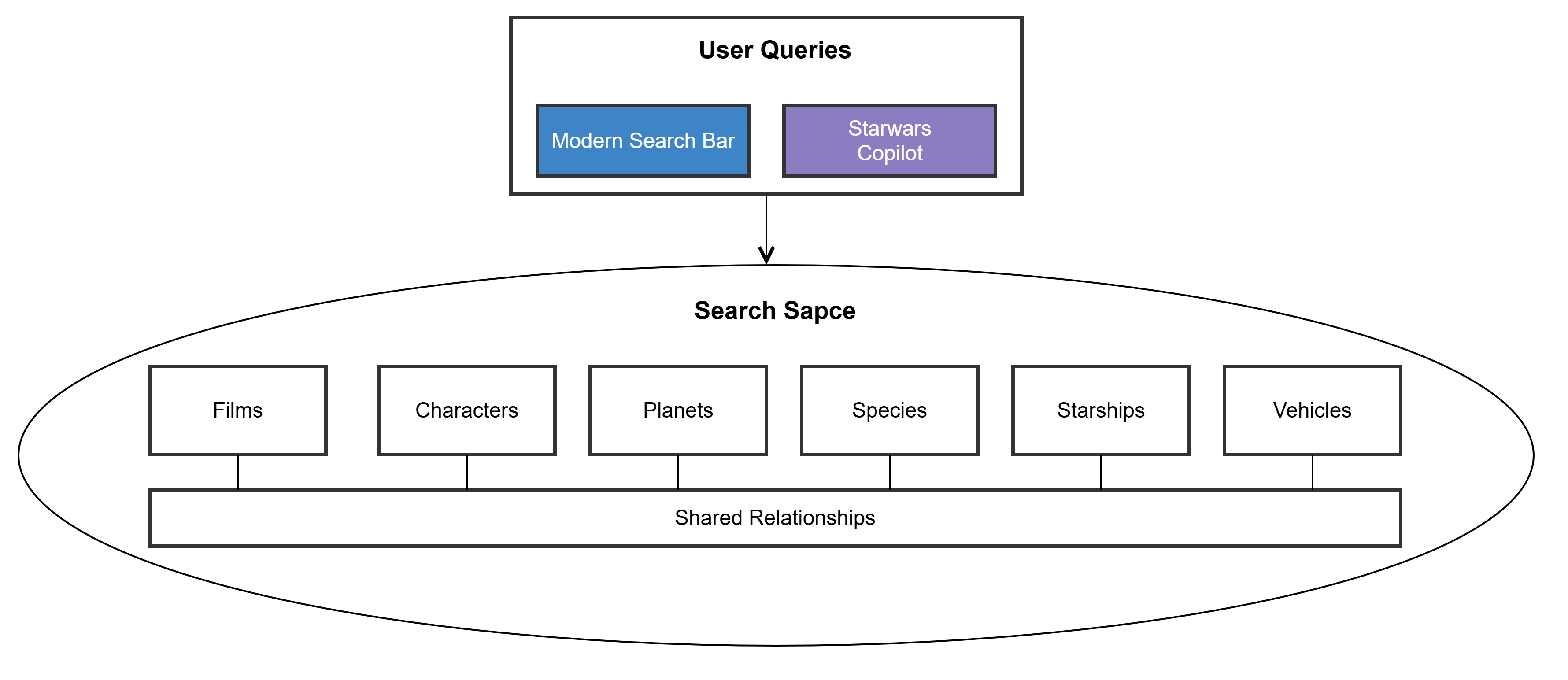
- Modern Search Experiences: A next-generation search paradigm where users expect answers instead of traditional search result links.
To achieve these goals, we set out to connect data across microservices without duplicating efforts or re-engineering APIs for every possible query. The key challenges include the fact that user queries come in various forms, not all of which have readily available APIs. Constantly modifying APIs to handle new queries isn't scalable, so we prioritised a generic and scalable solution by using the right toolset for the right job.
This led us to explore various methodologies, from traditional REST APIs and OpenAPI specifications to newer, more dynamic approaches like GraphQL and Elasticsearch. Below, we provide a deep dive into the different integration approaches and the lessons learned from each.
Exploring the Various Approaches for LLM Integration
To understand the optimal way to integrate LLMs into enterprise systems, we evaluated several approaches, each with distinct advantages and challenges:
Note: We have used the Star Wars data set in all our experiments. Please refer to the Appendix Section for more details
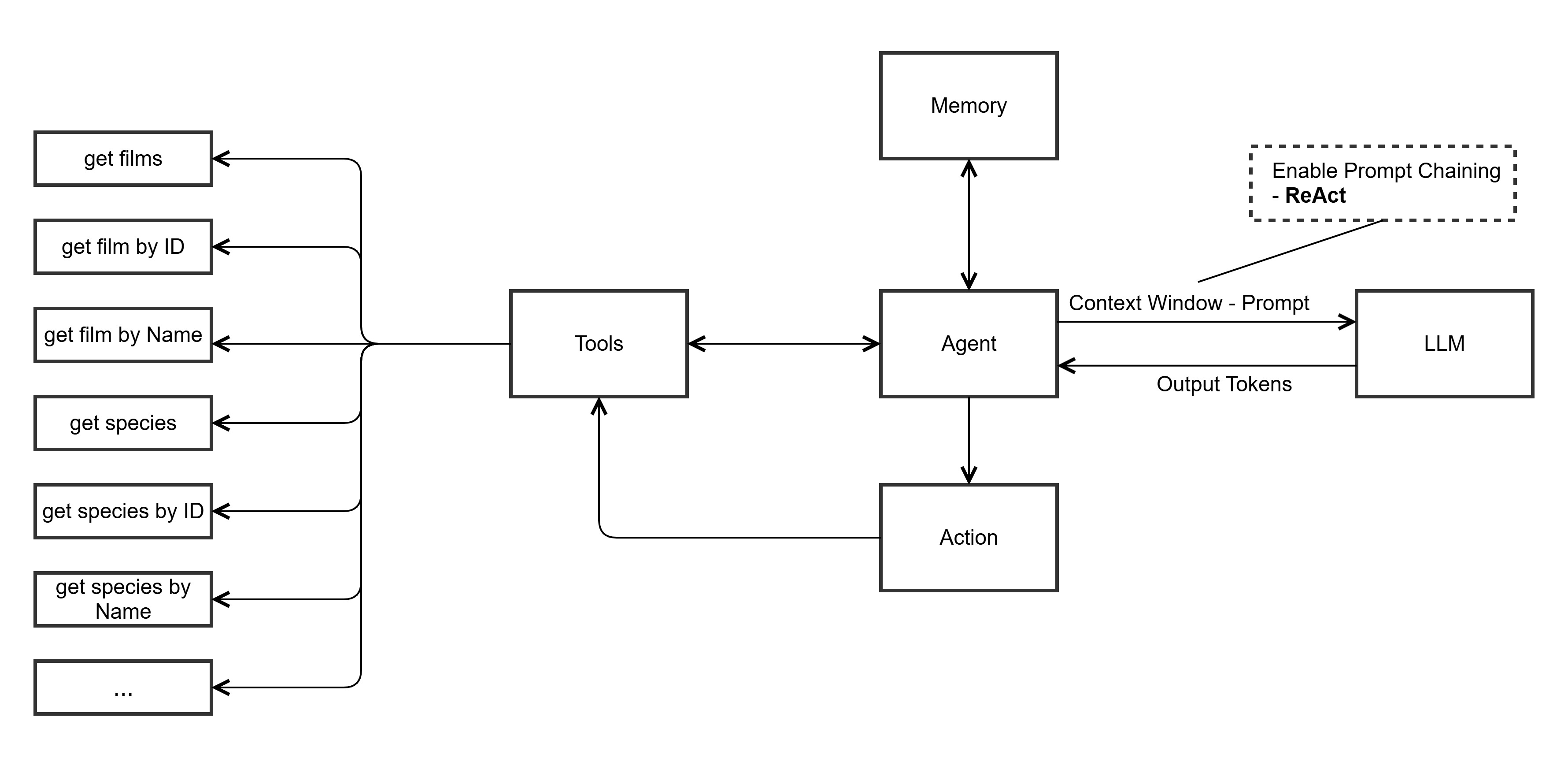
Single Agent with Multiple APIs (Traditional REST)
We compared this traditional approach to using multiple API endpoints for data retrieval, including REST and OpenAPI specifications.
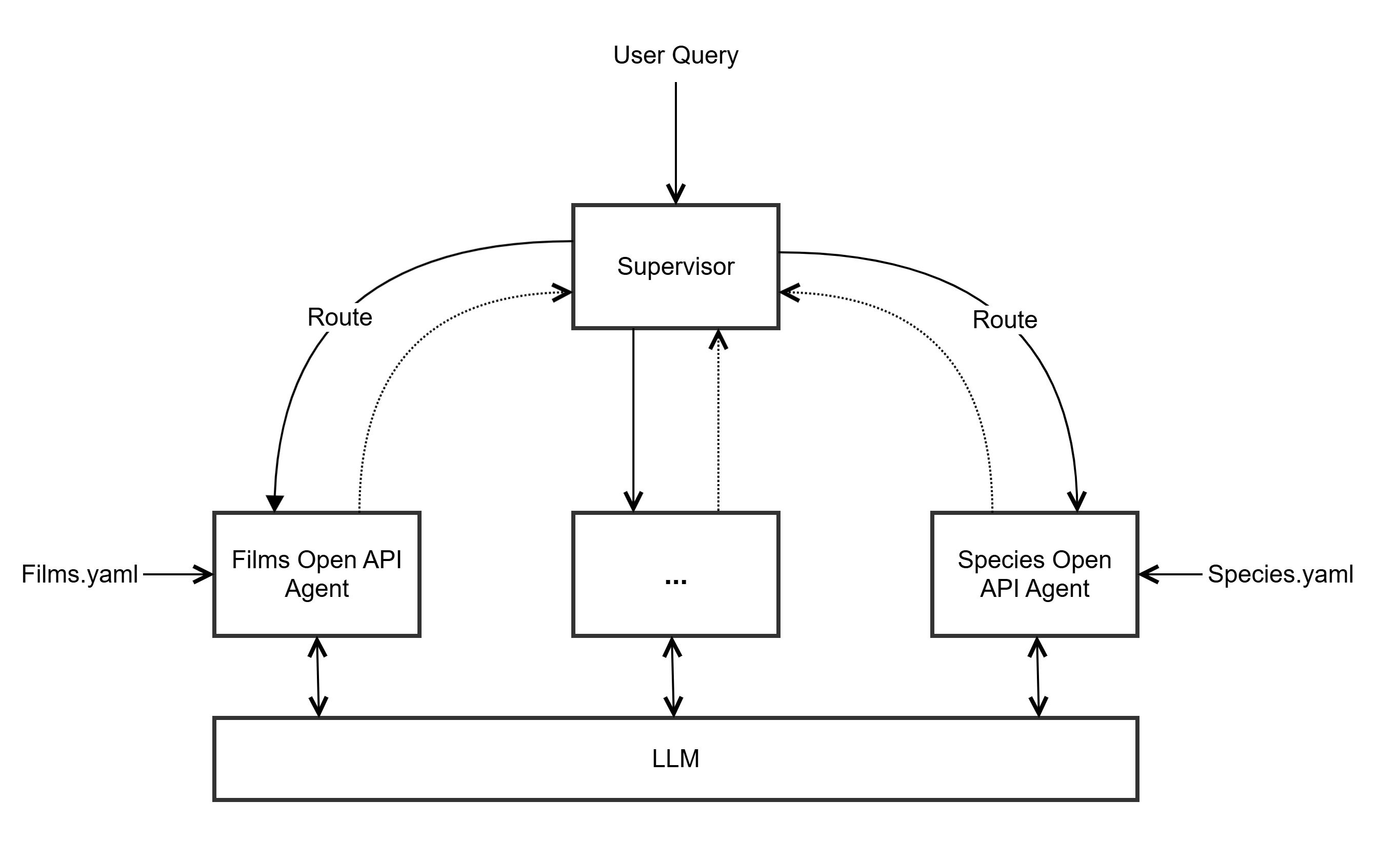
Multi-Agent Approach (Holistic OpenAPI)
A multi-agent model where each service (e.g., Films, Characters, Species) operates as an individual agent with its own OpenAPI specification.
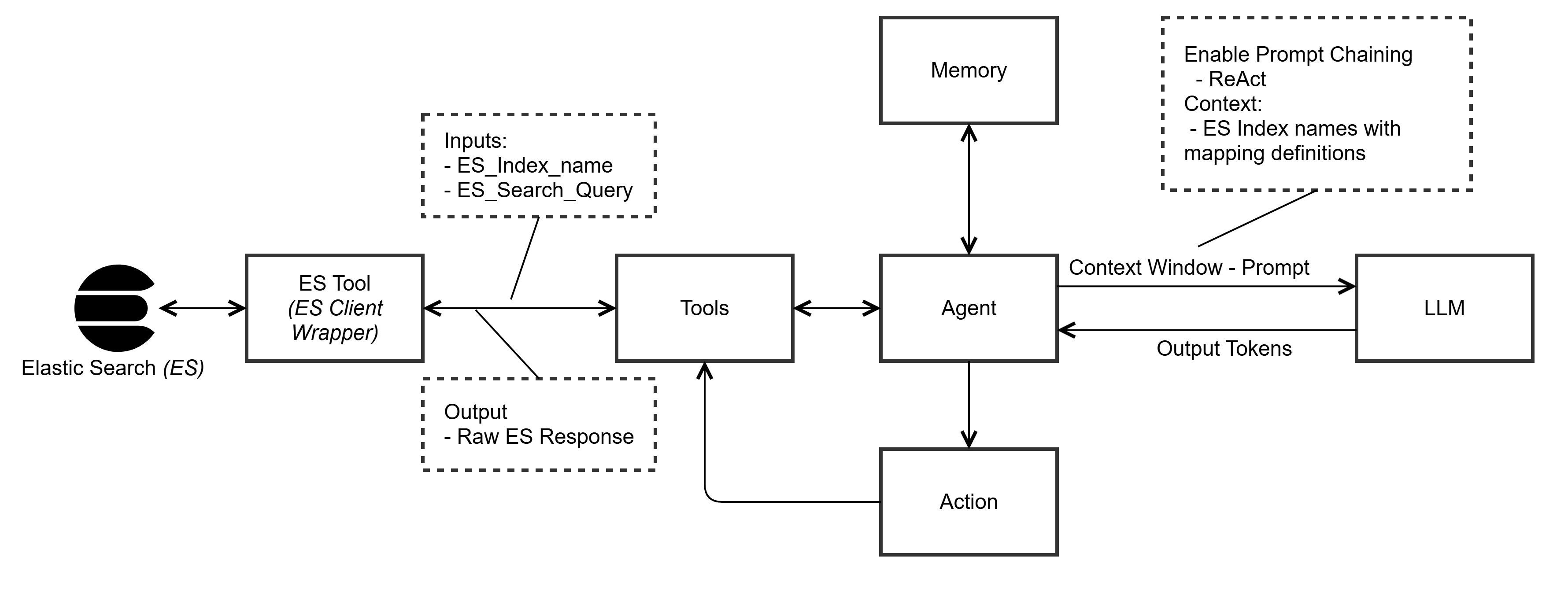
Universal Search API Powered by Elasticsearch (Elasticsearch)
Lastly, we tested Elasticsearch’s ability to manage large-scale, unstructured queries across multiple entities.
Single Agent with GraphQL Tool (GraphQL)
This method leverages GraphQL’s ability to retrieve only the necessary data in response to LLM queries, reducing token consumption and improving efficiency.
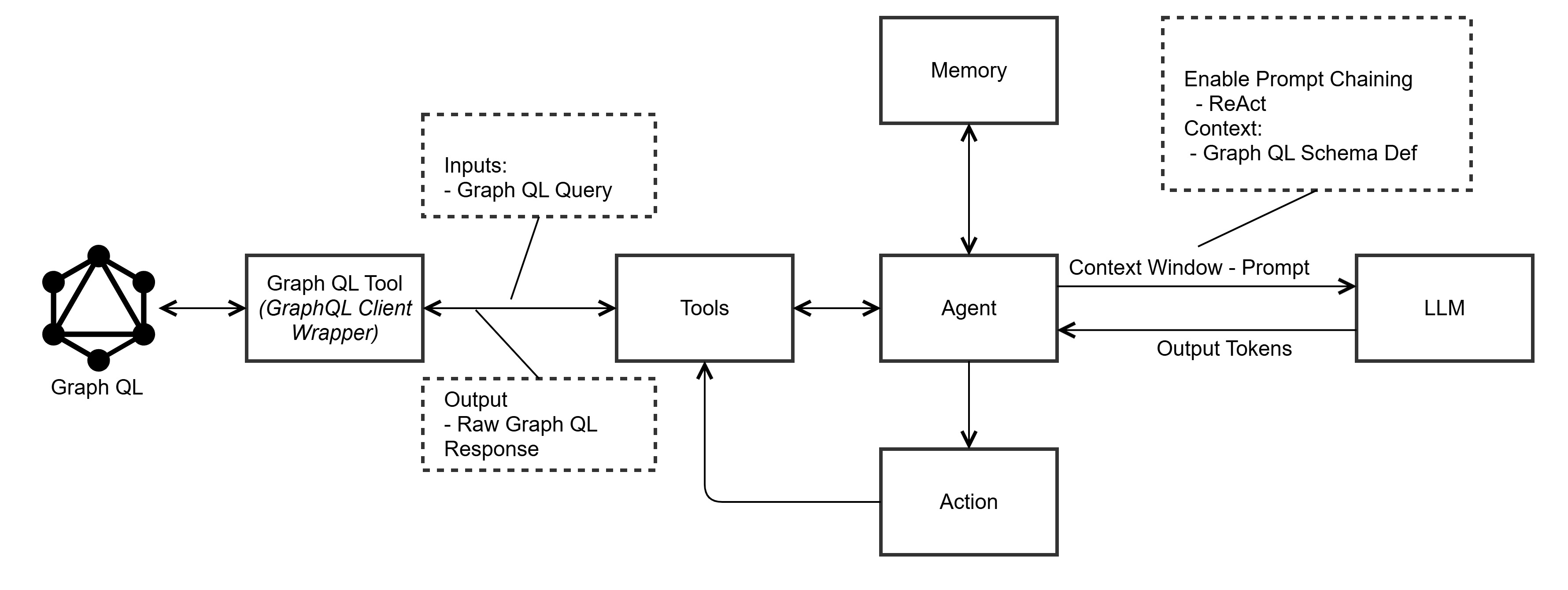
Dynamic Relationship Creation with GraphQL
GraphQL stands out for its ability to dynamically create relationships between data entities, making it especially useful for handling complex, cross-entity queries. Consider a query like "What species appear in The Empire Strikes Back?". In a Traditional REST or Holistic OpenAPI environment, this would involve multiple calls to various endpoints (e.g., Films, Species, Characters) to retrieve the required data. This leads to redundant or inefficient data fetching.
With GraphQL, however, relationships between entities (e.g., films, characters, species) are established on-the-fly, meaning fewer API calls, reduced latency, and lower token consumption. This flexibility is a key advantage in LLM-driven applications, where dynamic queries and real-time data retrieval are critical.
Token Efficiency and Cost Savings
In addition to flexibility, GraphQL significantly reduces the number of tokens consumed in LLM-powered applications. Since LLMs rely on tokens to process input and generate output, reducing token usage directly translates into cost savings. Traditional REST and Holistic OpenAPI often result in over-fetching of data, consuming more tokens than necessary. GraphQL’s precision in fetching only the required data minimises this problem, optimising token consumption.
Simple Queries
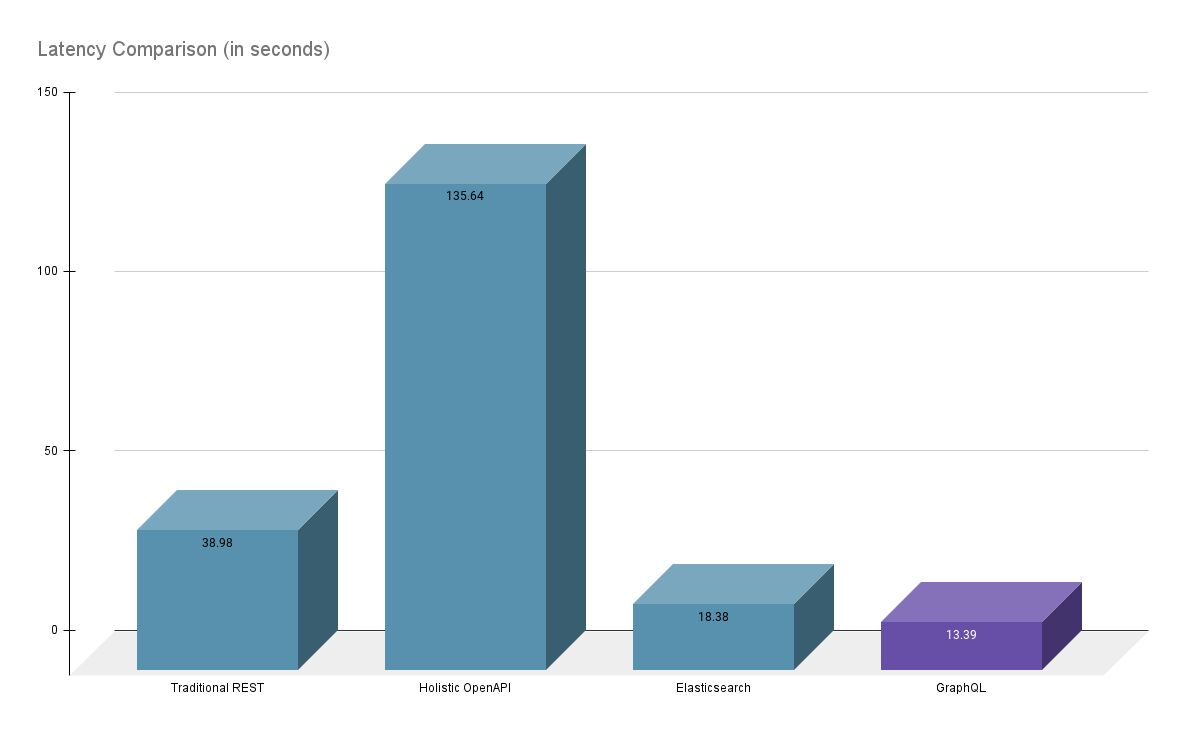
Here's a comparative analysis of latency and token usage across the different approaches: What species appear in The Empire Strikes Back?
For the same example, the token consumption is plotted below
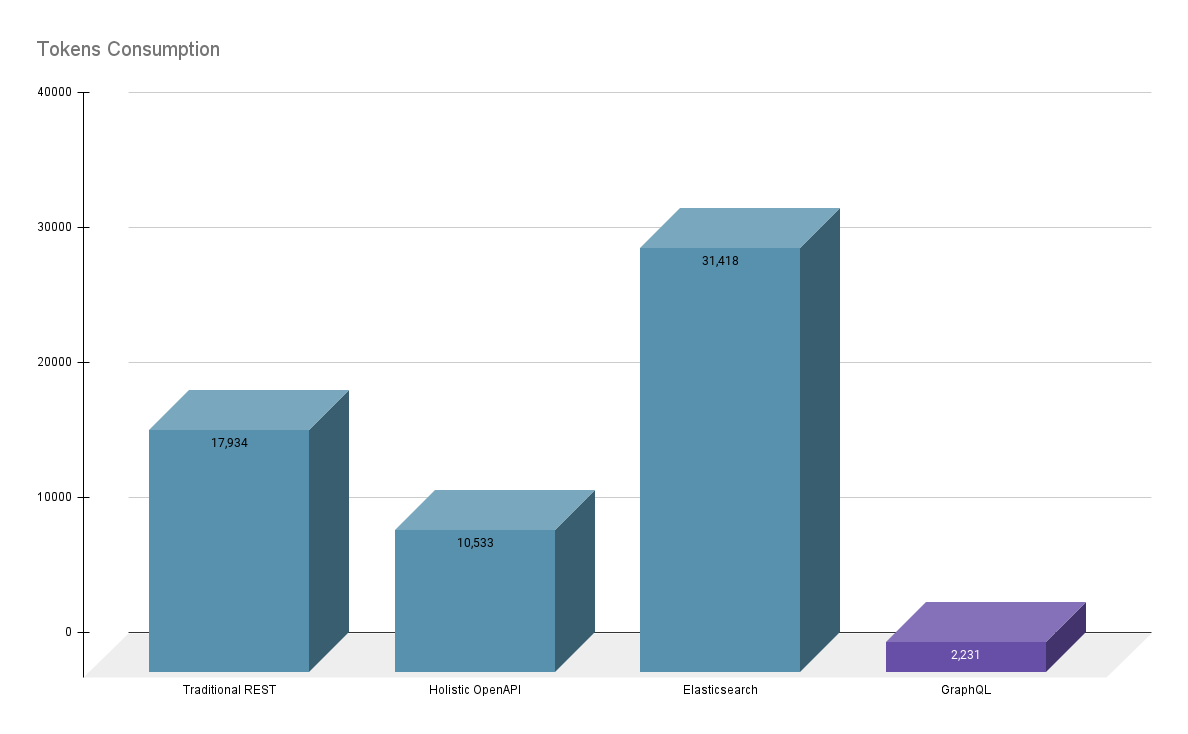
As shown in the charts, GraphQL outperforms traditional REST and OpenAPI approaches in both speed and efficiency, making it the clear winner for structured queries in LLM-based applications.
Varying-Complexity Queries
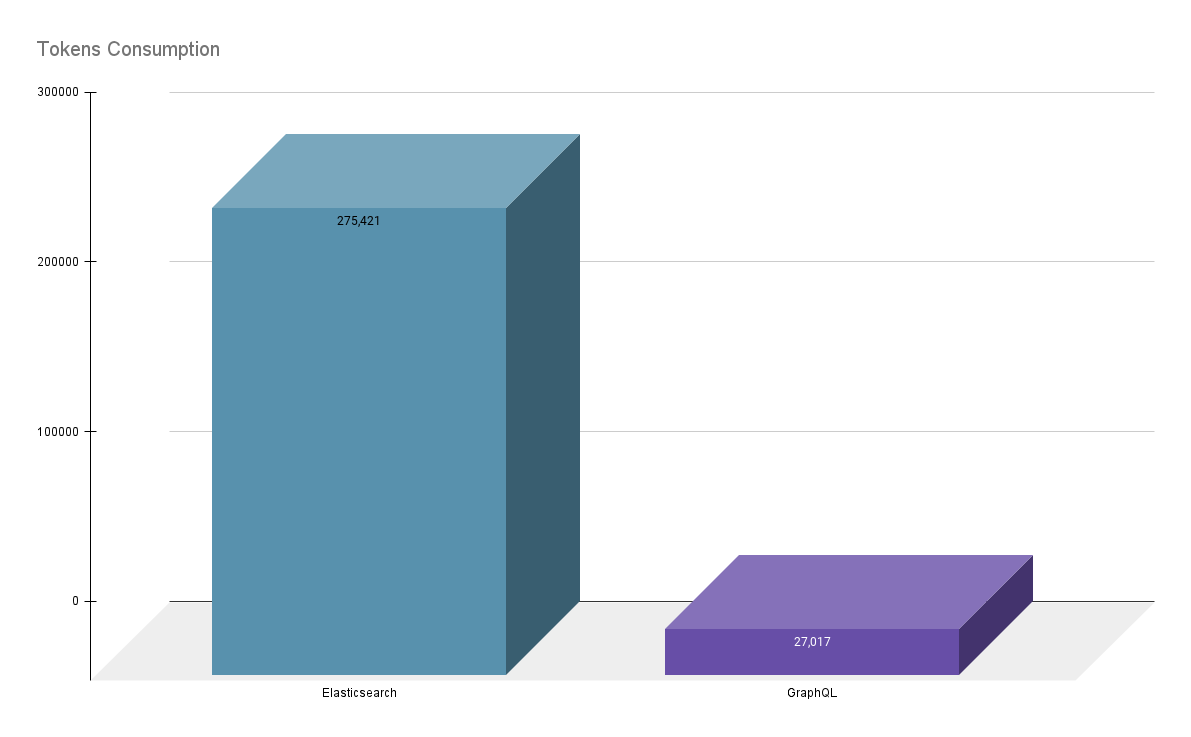
Although the Single Agent with GraphQL Tool and Universal Search API powered by Elasticsearch appear close in terms of latency, GraphQL still outperforms Elasticsearch in terms of accuracy across a range of complex user queries. This is primarily because, when integrating LLMs with Elasticsearch, we are passing only the index definitions, not the full Elasticsearch Query Language syntax. If the LLM inaccurately generates the query syntax, it can lead to wildcard queries that retrieve excessive data, causing cascading issues such as increased token usage and exceeding the LLM's context limits. Just to concretely illustrate this fact, below is the tokens consumption graph that we have observed across a set of queries of varying complexity.
The list of queries used for this comparison include:
- What species appear in The Empire Strikes Back?
- Get a timeline of the Star Wars movies based on their release dates and the main characters introduced in each movie.
- Get a relational view of all starships and characters who piloted them, including the films they appeared in.
Elasticsearch and NLP: Enhancing Unstructured Query Capabilities
While GraphQL excels in handling structured queries, it’s not always suited for unstructured data, where the complexity of natural language queries comes into play. This is where Elasticsearch provides significant value, especially in domain-driven NLP tasks. Elasticsearch’s full-text/vector search capabilities make it ideal for handling unstructured queries, offering powerful solutions such as:
- Spell correction: Automatically correcting typos and spelling errors in queries.
- Query rephrasing: Adjusting user queries to enhance the relevance of search results.
- Term expansion: Including synonyms or related terms to broaden search results.
However, we found that Elasticsearch’s schema isn’t always sufficient for structured queries when working with LLMs. The optimal approach involves combining GraphQL for structured queries with Elasticsearch for unstructured data, creating a highly efficient and dynamic search experience.
Hybrid Approach: The Best of Both Worlds
Based on our empirical results, we recommend a hybrid approach that leverages both GraphQL and Elasticsearch:
- GraphQL for structured queries, where token efficiency and speed are critical.
- Elasticsearch for unstructured queries, where full-text/vector search capabilities offer greater flexibility.
This hybrid solution offers a modern search experience, providing answers rather than links, and delivering fast, relevant results with minimal latency.
By combining GraphQL’s precision for structured data and Elasticsearch’s power for handling unstructured data, enterprises can unlock a seamless user experience that scales efficiently across complex datasets.
Early Adoption: A Competitive Advantage
In conclusion, early adoption of GraphQL as the foundation for LLM-driven systems is a game-changer for enterprises. When combined with Elasticsearch, it provides a scalable, cost-effective, and high-performance solution that can handle both structured and unstructured queries with ease.
Key takeaways include:
- Cost Savings: By minimising token usage, businesses can significantly lower operating expenses.
- Speed and Latency: GraphQL’s efficiency ensures faster response times, while Elasticsearch enhances unstructured data handling.
- Scalability: The flexibility of GraphQL and Elasticsearch ensures that systems can grow without constantly re-engineering APIs.
For enterprises looking to stay ahead of the curve, adopting GraphQL and Elasticsearch now can help future-proof AI-powered applications, delivering better performance, lower costs, and a more dynamic search experience.
Appendix
Star Wars: Core Dataset for Our Experiments
To evaluate the effectiveness of these approaches, we used Star Wars as our core example dataset. The Star Wars universe provides a rich, interconnected set of entities that perfectly mirrors the challenges of querying across microservices in real-world applications.
Key Entities and Relationships:
- Films: "A New Hope", "The Empire Strikes Back", etc.
- Characters: Han Solo, Luke Skywalker, Leia Organa
- Species: Human, Droid, Wookie
- Planets: Tatooine, Endor, Hoth
- Starships and Vehicles: Millennium Falcon, X-Wing
Each of these entities has a one-to-many or many-to-many relationship with other entities, and querying these relationships is a central challenge. For instance, a query like “What species appear in specific films?” requires fetching related data across films, species, and characters. We modelled each of these entities as bounded contexts, allowing us to build microservices that represent each entity individually (e.g., a Films Service, Characters Service, Species Service).
By using GraphQL, we were able to navigate these complex relationships dynamically, delivering precise answers without over-fetching data. This helped minimise API calls and reduce latency, particularly when handling queries that spanned multiple entities.
Star Wars - Domain Understanding
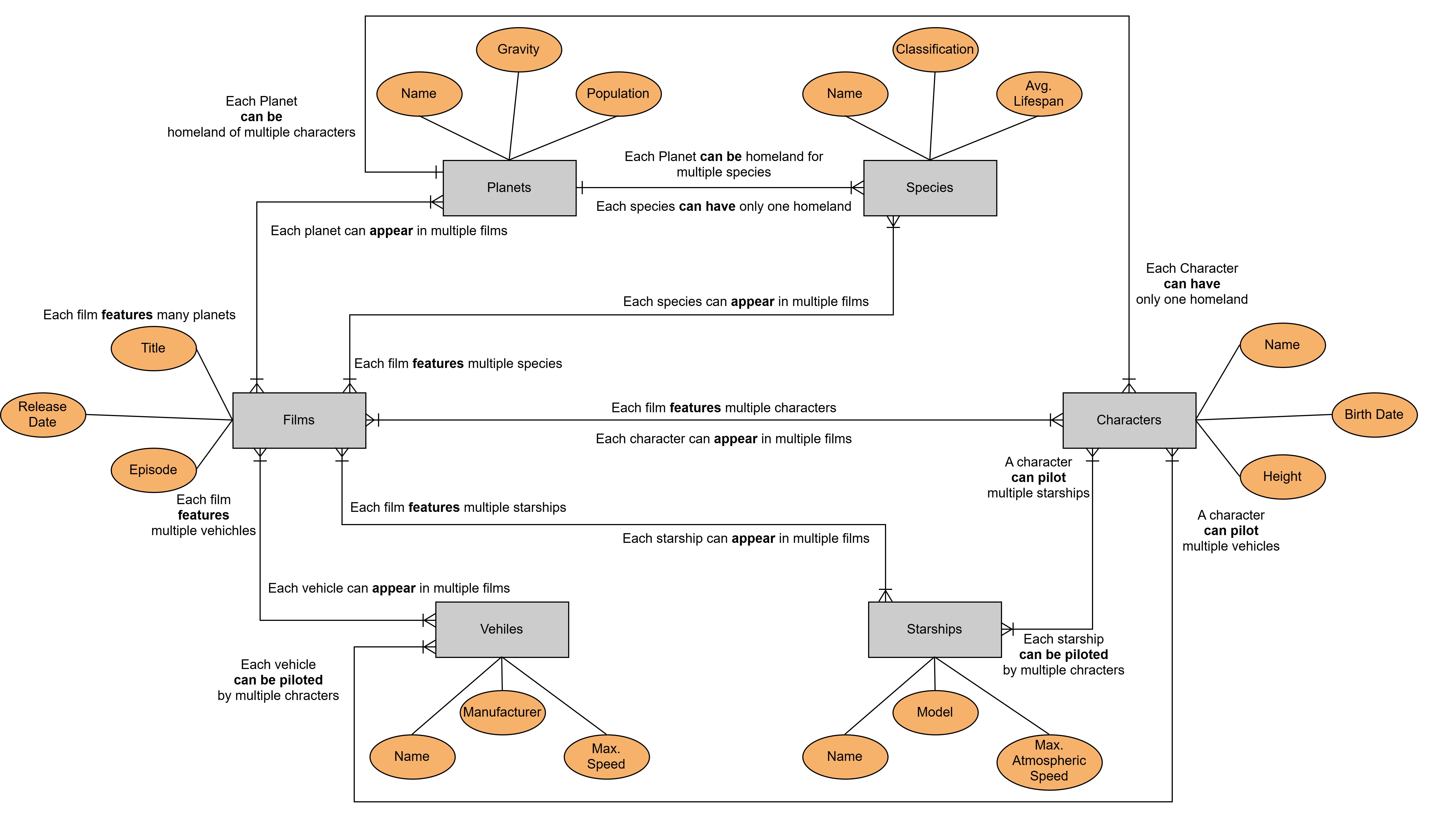
Domain Modelling - Entities as Bounded Contexts
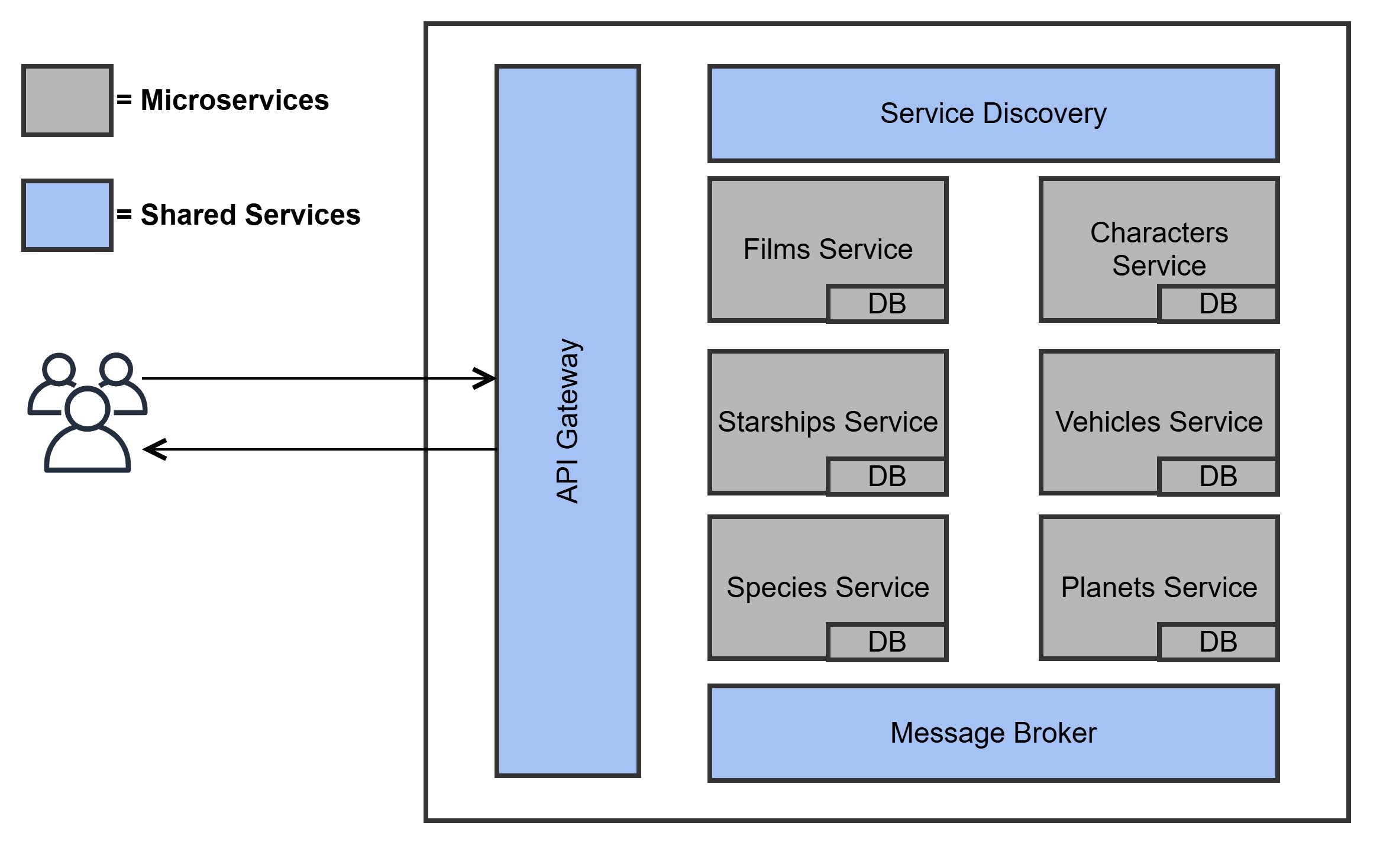
Star Wars Domain - Search Space